
Model Predictive Path Integral Control
February 2024 - April 2024
- Tech Stack: C++, ROS, Git
- Summary
Implemented MPPI on an RC car platform using C++ and ROS to enable aggressive driving.
Accomplished obstacle avoidance by utilizing a Costmap generated by a Voxel Grid.
Benchmarked MPPI against an existing iLQR controller, demonstrating faster path generation of up to 21% with MPPI.
My role: Helped implement MPPI, integrated the Costmap, and integrated with the rest of the software stack.
- In-Depth
Introduction
This project was completed as part of the Optimal Control and Reinforcement Learning (16-745) course at CMU. The aim of this project was to implement a Model Predictive Path Integral (MPPI) control algorithm for an RC car platform, and compare its performance with an existing Iterative Linear Quadratic Regulator (iLQR) controller. Traditional approaches like iLQR involve decoupling the planner and the controller. However, MPPI couples both of them, eliminating the need for a separate planner. The iLQR implementation uses the FALCO planner, which uses a fixed set of pre-generated paths that are computed offline. In contrast, our MPPI implementation randomly samples control sequences and rolls them out, which can lead to paths that could not have been achieved by the FALCO planner. This enables the MPPI to attain more aggressive paths. Our implemented MPPI controller outperforms our system's current iLQR/FALCO control/planning stack by generating faster paths.

Fig-1 Project RC Car Motivation
In more recent years, the focus on aggressive off-road autonomy has increased. Programs like DARPA Racer have accelerated academic research in this domain. In doing so, some traditional planning and control methods hit their limits due to challenging new terrain. As such, new methods have been derived to increase the speed and versatility of off-road autonomy systems. To this end, Model Predictive Path Integral (MPPI) control was introduced to fuse the planning and control steps. Our team thought this would be very interesting to study because it was related to the ongoing projects in our lab. We had a multi-robot system of RC cars that we drove to explore tunnels for military and search and rescue applications. Each car was controlled with an iLQR controller with the FALCO local planner running on the vehicles. That system was functional, but we were interested in running MPPI on our system to see how it compared to the current autonomy stack. As such, in this work, we developed MPPI for a simulated RC Car, and compared it to an iLQR and FALCO planning stack.MPPI vs iLQR/FALCO
This section will give a brief comparison of iLQR/FALCO and our MPPI implementation.iLQR/FALCO
Our FALCO implementation uses the Kinematic Bicycle Model above to build a parameterized set of possible paths offline. Paths are parameterized by speed. So, in the planning step, using the estimated robot speed, a set of paths is rolled out in "front" of the current estimated position of the robot. Assuming deterministic knowledge of obstacles, paths that intersect obstacles are removed. Finally, the path that minimizes distance to the goal is selected and used as the reference path. The generated paths and the selected path can be seen below in Fig-2, where the generated paths are red and the selected path is green. iLQR is used to control the car to the reference path. This allows for optimal control to the paths generated by the nonlinear KBM. Additionally, this supports inequality constraints on steering and velocity inputs in our system. At the rate of the system update, the system will receive a new path from the FALCO planner, and rerun the iLQR controller.

Fig-2 Visualization of pre-generated reference paths (red) and FALCO selected path (green) MPPI
Rather than including a planning and control step, MPPI combines these steps. MPPI does this by rolling out a sequence of paths. To roll out one path, MPPI samples a sequence of control inputs over the steps. Then, using a predefined cost function, the cost of each rollout is calculated. This process occurs for N number of rollouts. Then, the final control sent to the system is calculated using the weighted average of all control inputs, where the weight is based directly on the cost of the path. Some advantages of MPPI include:- Combines the planner and controller into a single entity, hence simplifying the pipeline.
- Possible to use highly non-convex cost functions and non-linear dynamics, as no optimization is involved. As a result more complicated dynamics models like Dynamic Bicycle Model can easily be implemented.
- Can achieve more aggressive and varied paths due to its sampling nature, whereas FALCO is limited to its set of pre-generated paths.
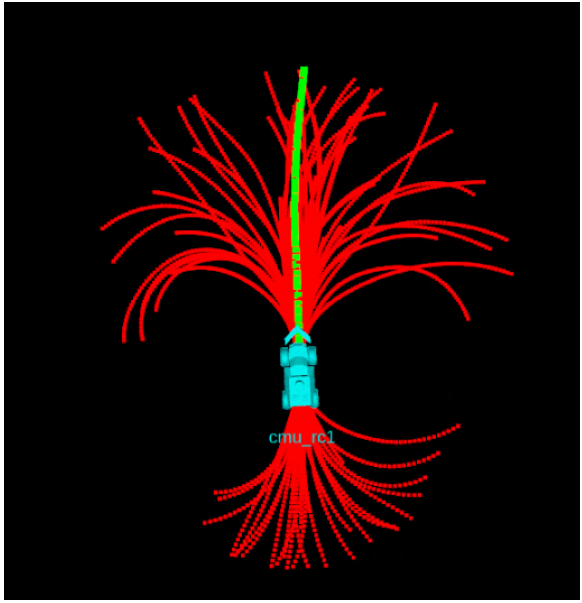
Fig-3 Visualization of sample-based roll outs (red) and ultimate MPPI-executed path (green)
- Results
We compared the results of waypoint following between iLQR and MPPI. We set 8 waypoints at different combinations of $x$ and $y$ positions. We tracked the distance from the final position of the car to the goal (Table-1). Additionally, we tracked the time it takes for the car to get to the goal position between the methods (Table-2).
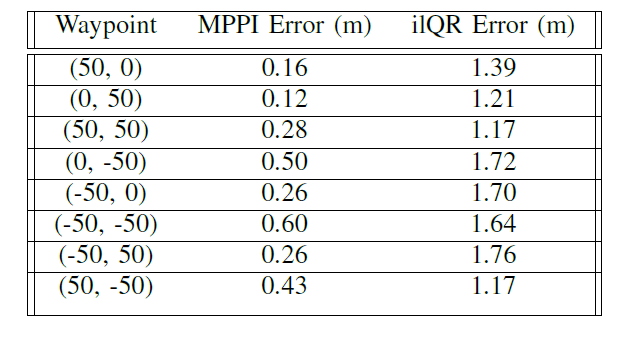
Table-1 Comparison of final position errors 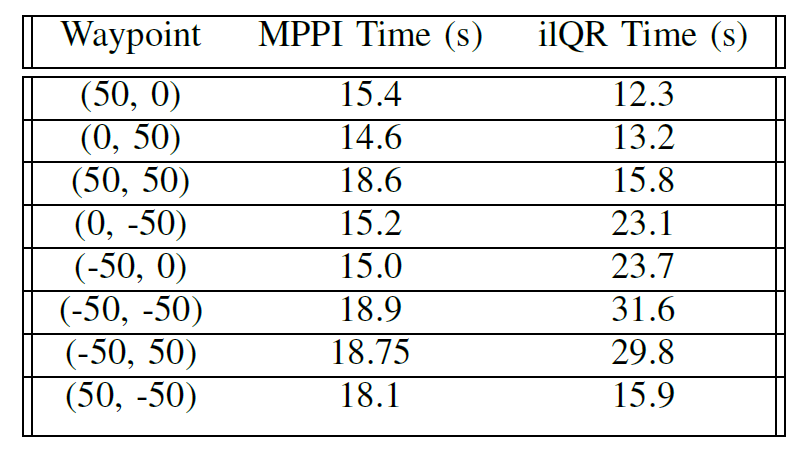
Table-2 Comparison of time taken to waypoint Overall, our results indicate that the final error of MPPI is lower. Where the average final error over all of the runs is 0.33m, and the average final error for iLQR is 1.47m. On average, iLQR took a bit longer, with an average of 20.67 seconds to completion while the time for MPPI was only 16.81 seconds. Over the course of one path, we compare the path taken by the car (Fig-4). We also compare the controlled velocity output (Fig-5) and the steering output (Fig-6).
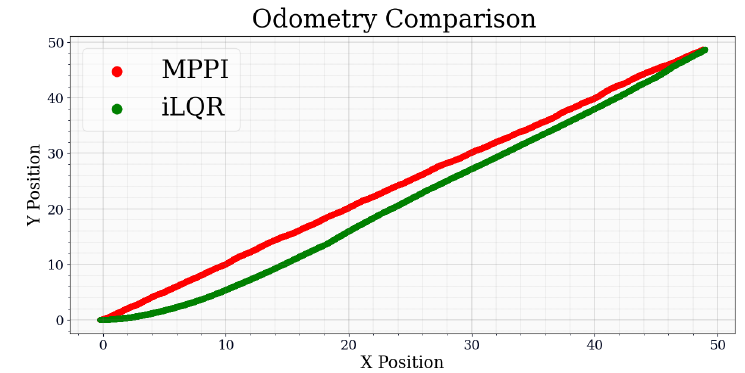
Fig-4 Path comparison of MPPI and iLQR 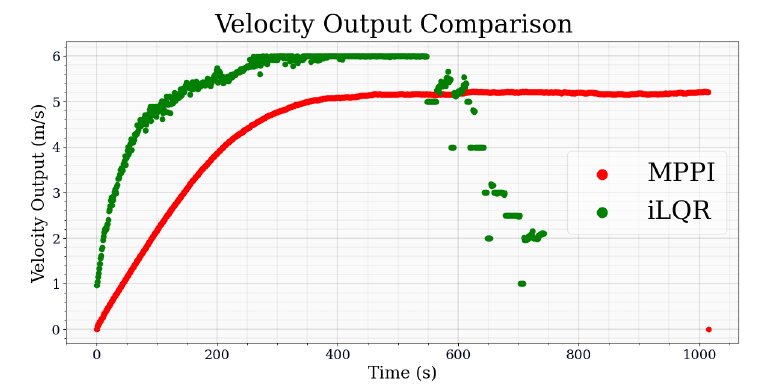
Fig-5 Velocity comparison of MPPI and iLQR 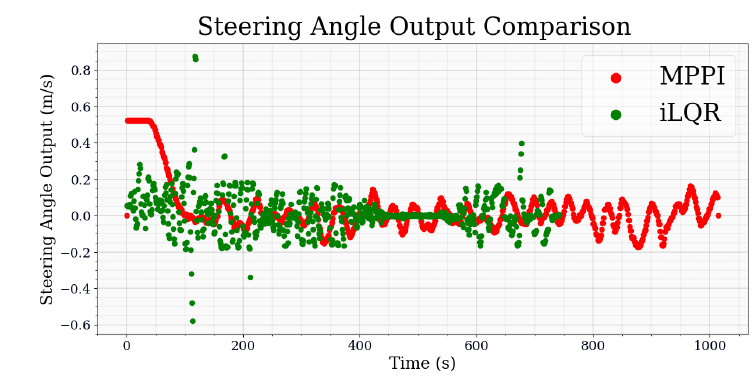
Fig-6 Steering angle comparison of MPPI and iLQR Our experiments demonstrate that MPPI has a lesser final error and faster speed of up to 21%, when compared to the iLQR. This is because MPPI is able to generate more direct and straight paths to the goal waypoint as compared to iLQR and FALCO, by virtue of sampling controls randomly and generating new and unique paths in real time.