
PinBot – Reinforcement Learning on a Pinball Machine
September 2024 - Present
- Tech Stack: Python, PyTorch, Unity, Git
- Summary
Developed a reinforcement learning agent using Proximal Policy Optimization (PPO) to play the pinball game Total Nuclear Annihilation.
Trained the agent in a simulated environment using the Gymnasium framework, outperforming a randomized baseline agent by 67%.
Applying transfer learning to adapt the agent for a physical pinball machine (ongoing work).
My role: Helped setup the simulation framework, and also worked on implementing PPO.
- In-Depth
Introduction
This project was completed as part of the Introduction to Robot Learning (16-831) course at CMU. The aim of this project was to apply reinforcement learning to play the classic arcade game of pinball. Two settings were considered - simulation and physical hardware. The performance of this agent was evaluated against human players.

Fig-1 The physical setup of the Pinball game of Total Nuclear Annihilation (TNA) Motivation
Reinforcement learning has been successfully applied to games like Go, Pong, and Dota 2. Games serve as ideal learning environments due to their defined boundaries, clear objectives, and opportunities for strategic decision making. Pinball is a classic arcade game in which a player uses two flippers to keep a ball on the playfield while attempting to hit various targets. Pinball is dynamic and requires highly reactive game play and control. The objective is to maximize the score of the game over the course of three balls (turns). This makes pinball an ideal candidate for training an RL agent, because the rewards and actions are very clearly defined.Methodology
A digital version of TNA was sourced from the Visual Pinball X project, and was trained in a simulation environment using the Unity ML-Agents framework. After training in sim, the goal was to use the learned weights and implement transfer learning for the physical game, as this would speed up training drastically. The RL model used for the same was Proximal Policy Optimization (PPO).PPO
The details of the training and model parameters are given below.State Space
The state/observation space is continuous, and includes five state observations: a downsampled image of the playfield; the ball’s x and y position; and the ball’s x and y velocity.Action Space
The action space is discrete, and includes a vector of four discrete actions. The first action, idle, releases the flippers. The second and third actions activate the left and right flippers, respectively. The fourth action activates both flippers simultaneously. The agent samples one action 20 times per second.Reward Function
The reward function is calculated by factoring in the score, play time, ball position, and ball loss. The score is the raw game score tracked by the machine, and it is the direct metric we seek to increase. A large penalty when a ball is lost to encourage the agent from prematurely ending a game. Furthermore, to encourage activity in the typically sparse environment, a small reward is added whenever the ball is on the field above the flippers, and detracted when at or below. This position-based reward is necessary, as a simple time-based award would reach a local minima where the agent simply traps the ball on the flipper. We sum these three components to get the reward function as shown in Fig-2.

Fig-2 Reward formulation Model Architecture
The current model is set relatively small, featuring 1 layer and 128 hidden units. Experimentation with more layers and units is needed, but a compact network was initially favored to prevent overfitting and reduce training time. A recurrent neural network (RNN) is used to give the agent a short-term memory of 35 frames (about 1.5 seconds). This allows the agent to better factor in the game dynamics, as a single game frame does not convey ball velocity or acceleration. For the game frame image, a simple encoder with two convolutional layers is used to transform frames to the agent’s space. The agent’s reward signals are influenced by a gamma γ of 0.99, encouraging the agent to care about long-term rewards. To update the model, an epsilon ϵ of 0.2 was used, which will keep the updates more stable, but slow the training process slightly. A learning rate of 3e − 4 is implemented, with a linear schedule.
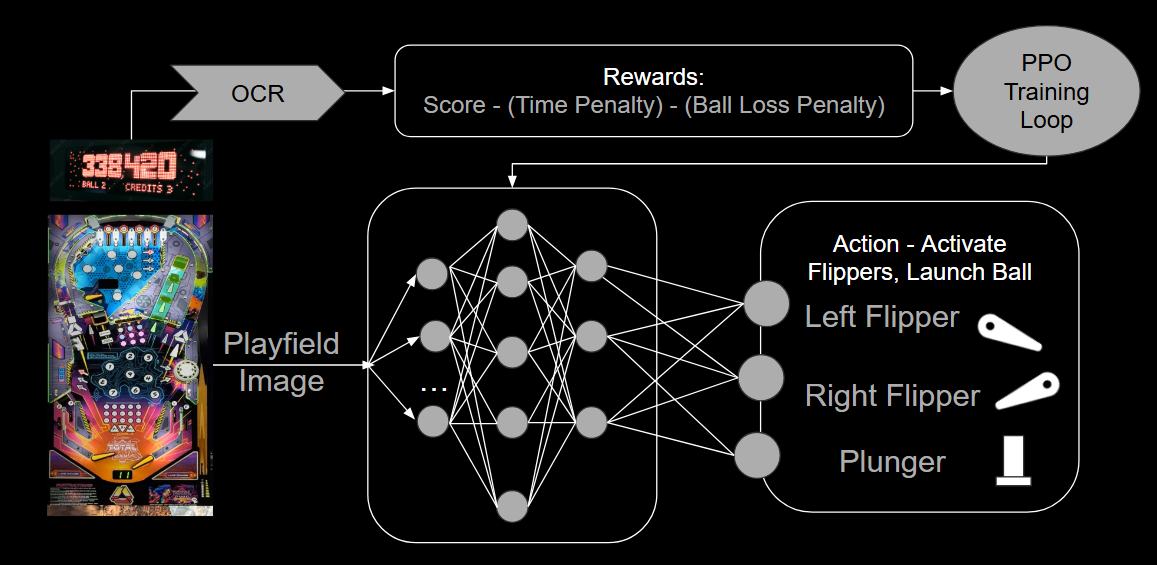
Fig-3 An overview of the training framework
- Results
After training for 90k steps, the model was evaluated against three baselines: a human player, a randomized agent, and no agent. 10 cases were run for each scenario, with aggregated results below.

Table-1 Performance of the trained agent compared against baselines 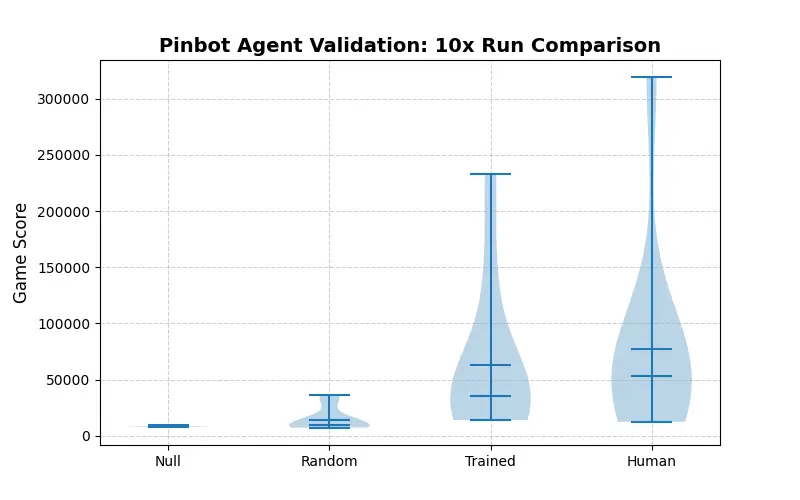
Fig-4 Violin plot of agent performance The AI in action - The agent had locked two balls, and was one shot away from getting a multi-ball In this work, we developed a reinforcement learning model to play pinball in simulation, showing heightened performance to random actions, and near-comparable performance to a human player.